Dataset
Extended Deformable Superquadrics
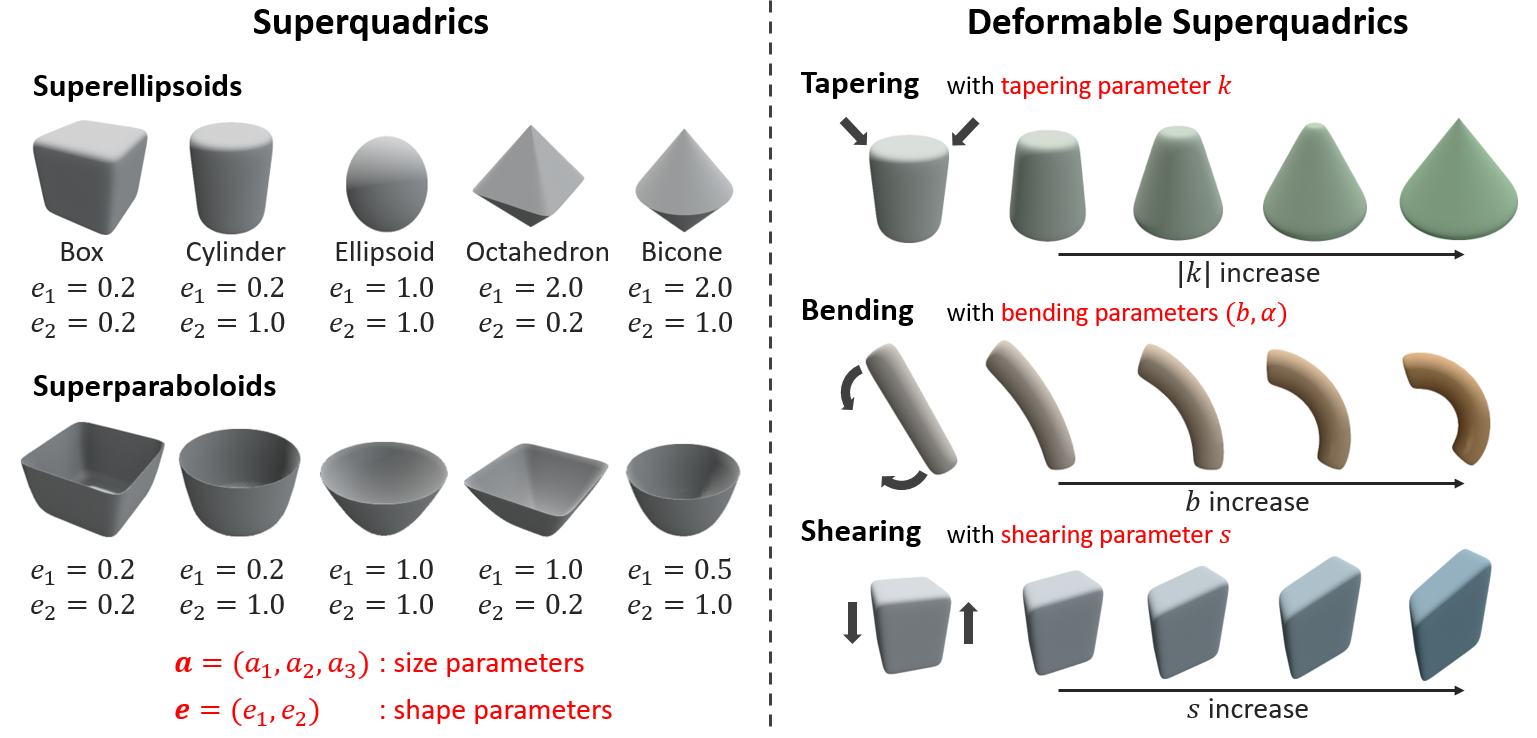
Superquadrics, parametrized by only a few parameters, can represent a relatively wide range of geometric shapes. We employ two kinds of superquadrics: superellipsoids, which have been used for object manipulation, and superparaboloids, which are newly introduced. Superellipsoids and superparaboloids are implicit surfaces with the following implicit functions with size parameters \((a_1, a_2, a_3) \in \mathbb{R}_+^3\) and shape parameters \((e_1, e_2) \in \mathbb{R}_+^2\): for \(\textbf{x} = (x, y, z)\), $$ \begin{equation*} \overbrace{f_{se}(\textbf{x})=\left(\left|\frac{x}{a_1}\right|^{\frac{2}{e_2}} + \left|\frac{y}{a_2}\right|^{\frac{2}{e_2}}\right)^{\frac{e_2}{e_1}} + \left|\frac{z}{a_3}\right|^{\frac{2}{e_1}} = 1 }^{\text{Superellipsoid}}, \:\:\:\:\:\: \overbrace{f_{sp}(\textbf{x})= \left(\left|\frac{x}{a_1}\right|^{\frac{2}{e_2}} + \left|\frac{y}{a_2}\right|^{\frac{2}{e_2}}\right)^{\frac{e_2}{e_1}} - \left(\frac{z}{a_3}\right) = 1}^{\text{Superparaboloid}} \label{eq:sq} \end{equation*} $$ Deformable superquadrics extend superquadrics by incorporating global deformations, including tapering, bending, and shearing transformations. By adjusting the parameters, various surfaces can be represented, as shown below.
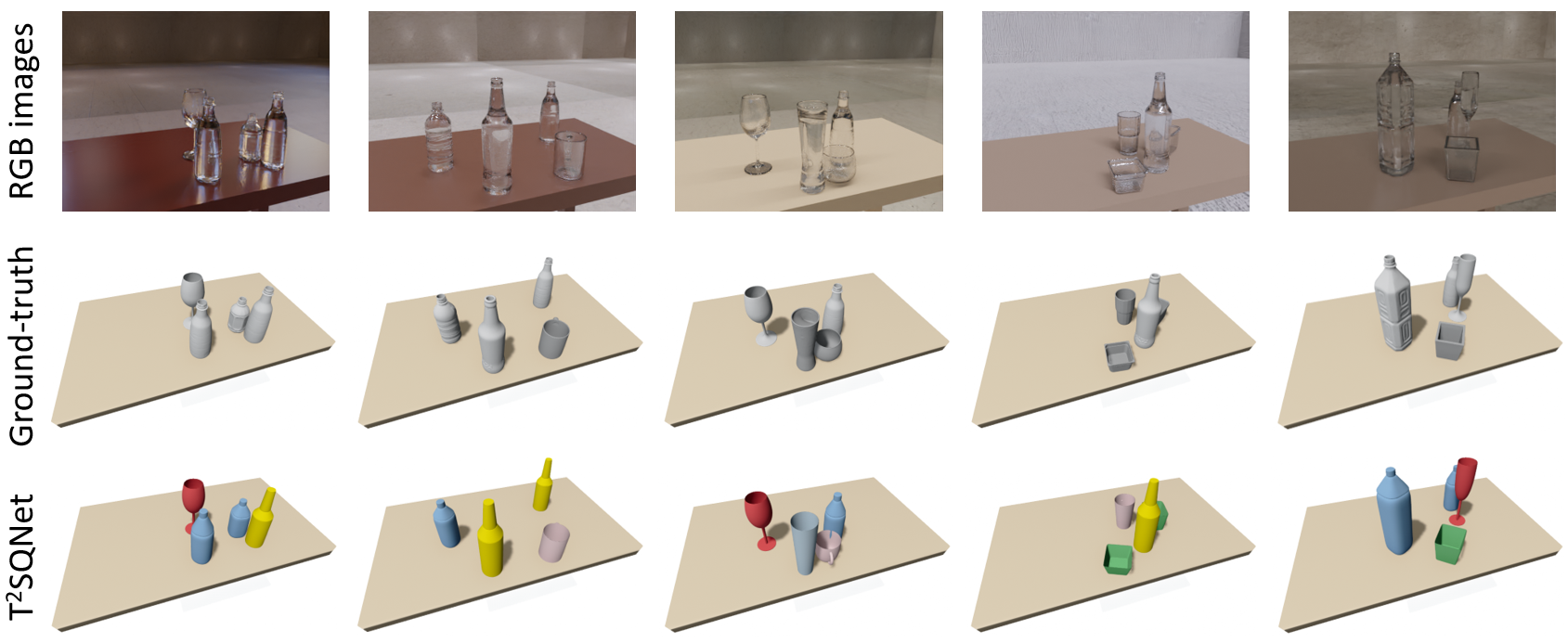
TablewareNet: Dataset for Cluttered Transparent Tableware
We combine deformable superquadrics to define templates representing seven types of tableware: wine glasses, bottles, beer bottles, bowls, dishes, handleless cups, and mugs. By adjusting parameters, we can generate diverse 3D tableware meshes. Spawning these meshes in a user-defined environment (e.g., table or shelf) within a physics simulator allows us to generate cluttered scenes. Using Blender, a photorealistic renderer, with transparent textures, we obtain RGB images of the scenes from arbitrary camera poses.